Searching string data for an arbitrary substring match can be an expensive operation in SQL Server. Queries of the form Column LIKE '%match%' cannot use the seeking abilities of a b-tree index, so the query processor has to apply the predicate to each row individually. In addition, each test must correctly apply the full set of complicated collation rules. Combining all these factors together, it is no surprise that these types of searches can be resource-intensive and slow.
Full-Text Search is a powerful tool for linguistic matching, and the newer Statistical Semantic Search is great for finding documents with similar meanings. But sometimes, you really just need to find strings that contain a particular substring – a substring that might not even be a word, in any language.
If the searched data is not large, or response time requirements are not critical, using LIKE '%match%' could well be a suitable solution. But, on the odd occasion where the need for a super-fast search beats all other considerations (including storage space), you might consider a custom solution using n-grams. The specific variation explored in this article is a three character trigram.
Wildcard searching using trigrams
The basic idea of a trigram search is quite simple:
- Persist three-character substrings (trigrams) of the target data.
- Split the search term(s) into trigrams.
- Match search trigrams against the stored trigrams (equality search)
- Intersect the qualified rows to find strings that match all trigrams
- Apply the original search filter to the much-reduced intersection
We will work through an example to see exactly how this all works, and what the trade-offs are.
Sample table and data
The script below creates an example table and populates it with a million rows of string data. Each string is 20 characters long, with the first 10 characters being numeric. The remaining 10 characters are a mixture of numbers and letters from A to F, generated using NEWID(). There is nothing terribly special about this sample data; the trigram technique is quite general.
-- The test table CREATE TABLE dbo.Example ( id integer IDENTITY NOT NULL, string char(20) NOT NULL, CONSTRAINT [PK dbo.Example (id)] PRIMARY KEY CLUSTERED (id) ); GO -- 1 million rows INSERT dbo.Example WITH (TABLOCKX) (string) SELECT TOP (1 * 1000 * 1000) -- 10 numeric characters REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') + -- plus 10 mixed numeric + [A-F] characters RIGHT(NEWID(), 10) FROM master.dbo.spt_values AS SV1 CROSS JOIN master.dbo.spt_values AS SV2 OPTION (MAXDOP 1);
It takes around 3 seconds to create and populate the data on my modest laptop. The data is pseudorandom, but as an indication it will look something like this:

Data sample
Generating trigrams
The following inline function generates distinct alphanumeric trigrams from a given input string:
--- Generate trigrams from a string CREATE FUNCTION dbo.GenerateTrigrams (@string varchar(255)) RETURNS table WITH SCHEMABINDING AS RETURN WITH N16 AS ( SELECT V.v FROM ( VALUES (0),(0),(0),(0),(0),(0),(0),(0), (0),(0),(0),(0),(0),(0),(0),(0) ) AS V (v)), -- Numbers table (256) Nums AS ( SELECT n = ROW_NUMBER() OVER (ORDER BY A.v) FROM N16 AS A CROSS JOIN N16 AS B ), Trigrams AS ( -- Every 3-character substring SELECT TOP (CASE WHEN LEN(@string) > 2 THEN LEN(@string) - 2 ELSE 0 END) trigram = SUBSTRING(@string, N.n, 3) FROM Nums AS N ORDER BY N.n ) -- Remove duplicates and ensure all three characters are alphanumeric SELECT DISTINCT T.trigram FROM Trigrams AS T WHERE -- Binary collation comparison so ranges work as expected T.trigram COLLATE Latin1_General_BIN2 NOT LIKE '%[^A-Z0-9a-z]%';
As an example of its use, the following call:
SELECT GT.trigram FROM dbo.GenerateTrigrams('SQLperformance.com') AS GT;
Produces the following trigrams:

SQLperformance.com trigrams
The execution plan is a fairly direct translation of the T-SQL in this case:
- Generating rows (cross join of Constant Scans)
- Row numbering (Segment and Sequence Project)
- Limiting the numbers needed based on the length of the string (Top)
- Remove trigrams with non-alphanumeric characters (Filter)
- Remove duplicates (Distinct Sort)

Plan for generating trigrams
Loading the trigrams
The next step is to persist trigrams for the example data. The trigrams will be held in a new table, populated using the inline function we just created:
-- Trigrams for Example table CREATE TABLE dbo.ExampleTrigrams ( id integer NOT NULL, trigram char(3) NOT NULL ); GO -- Generate trigrams INSERT dbo.ExampleTrigrams WITH (TABLOCKX) (id, trigram) SELECT E.id, GT.trigram FROM dbo.Example AS E CROSS APPLY dbo.GenerateTrigrams(E.string) AS GT;
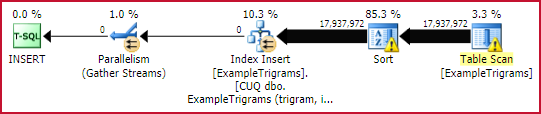
That takes around 20 seconds to execute on my SQL Server 2016 laptop instance. This particular run produced 17,937,972 rows of trigrams for the 1 million rows of 20-character test data. The execution plan essentially shows the function plan being evaluated for each row of the Example table:

Populating the trigram table
Since this test was performed on SQL Server 2016 (loading a heap table, under database compatibility level 130, and with a TABLOCK hint), the plan benefits from parallel insert. Rows are distributed between threads by the parallel scan of the Example table, and remain on the same thread thereafter (no repartitioning exchanges).
The Sort operator might look a bit imposing, but the numbers show the total number of rows sorted, over all iterations of the nested loop join. In fact, there are a million separate sorts, of 18 rows each. At a degree of parallelism of four (two cores hyperthreaded in my case), there are a maximum of four tiny sorts going on at any one time, and each sort instance can reuse memory. This explains why the maximum memory use of this execution plan is a mere 136KB (though 2,152 KB was granted).
The trigrams table contains one row for each distinct trigram in each source table row (identified by id):
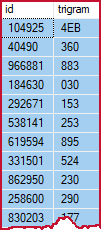
Trigram table sample
We now create a clustered b-tree index to support searching for trigram matches:
-- Trigram search index CREATE UNIQUE CLUSTERED INDEX [CUQ dbo.ExampleTrigrams (trigram, id)] ON dbo.ExampleTrigrams (trigram, id) WITH (DATA_COMPRESSION = ROW);
This takes around 45 seconds, though some of that is due to the sort spilling (my instance is limited to 4GB memory). An instance with more memory available could probably complete that minimally-logged parallel index build quite a bit faster.
Index building plan
Notice that the index is specified as unique (using both columns in the key). We could have created a non-unique clustered index on the trigram alone, but SQL Server would have added 4-byte uniquifiers to almost all rows anyway. Once we factor in that uniquifiers are stored in the variable-length part of the row (with the associated overhead), it just makes more sense to include id in the key and be done with it.
Row compression is specified because it usefully reduces the size of the trigram table from 277MB to 190MB (for comparison, the Example table is 32MB). If you are not at least using SQL Server 2016 SP1 (where data compression became available for all editions) you can omit the compression clause if necessary.
As a final optimization, we will also create an indexed view over the trigrams table to make it fast and easy to find which trigrams are the most and least common in the data. This step can be omitted, but is recommended for performance.
-- Selectivity of each trigram (performance optimization) CREATE VIEW dbo.ExampleTrigramCounts WITH SCHEMABINDING AS SELECT ET.trigram, cnt = COUNT_BIG(*) FROM dbo.ExampleTrigrams AS ET GROUP BY ET.trigram; GO -- Materialize the view CREATE UNIQUE CLUSTERED INDEX [CUQ dbo.ExampleTrigramCounts (trigram)] ON dbo.ExampleTrigramCounts (trigram);

Indexed view building plan
This only takes a couple of seconds to complete. The size of the materialized view is tiny, just 104KB.
Trigram search
Given a search string (e.g. '%find%this%'), our approach will be to:
- Generate the complete set of trigrams for the search string
- Use the indexed view to find the three most selective trigrams
- Find the ids matching all available trigrams
- Retrieve the strings by id
- Apply the full filter to the trigram-qualified rows
Finding selective trigrams
The first two steps are pretty straightforward. We already have a function to generate trigrams for an arbitrary string. Finding the most selective of those trigrams can be achieved by joining to the indexed view. The following code wraps the implementation for our example table in another inline function. It pivots the three most selective trigrams into a single row for ease of use later on:
-- Most selective trigrams for a search string -- Always returns a row (NULLs if no trigrams found) CREATE FUNCTION dbo.Example_GetBestTrigrams (@string varchar(255)) RETURNS table WITH SCHEMABINDING AS RETURN SELECT -- Pivot trigram1 = MAX(CASE WHEN BT.rn = 1 THEN BT.trigram END), trigram2 = MAX(CASE WHEN BT.rn = 2 THEN BT.trigram END), trigram3 = MAX(CASE WHEN BT.rn = 3 THEN BT.trigram END) FROM ( -- Generate trigrams for the search string -- and choose the most selective three SELECT TOP (3) rn = ROW_NUMBER() OVER ( ORDER BY ETC.cnt ASC), GT.trigram FROM dbo.GenerateTrigrams(@string) AS GT JOIN dbo.ExampleTrigramCounts AS ETC WITH (NOEXPAND) ON ETC.trigram = GT.trigram ORDER BY ETC.cnt ASC ) AS BT;
As an example:
SELECT EGBT.trigram1, EGBT.trigram2, EGBT.trigram3 FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT;
returns (for my sample data):

Selected trigrams
The execution plan is:
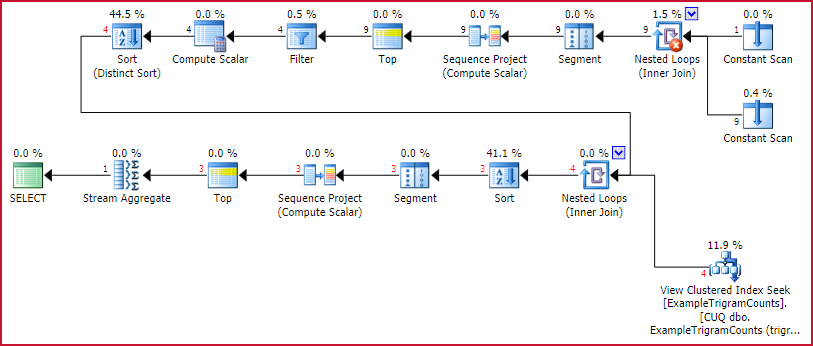
GetBestTrigrams execution plan
This is the familiar trigram-generating plan from earlier, followed by a lookup into the indexed view for each trigram, sorting by the number of matches, numbering the rows (Sequence Project), limiting the set to three rows (Top), then pivoting the result (Stream Aggregate).
Finding IDs matching all trigrams
The next step is to find Example table row ids that match all of the non-null trigrams retrieved by the previous stage. The wrinkle here is that we may have zero, one, two, or three trigrams available. The following implementation wraps the necessary logic in a multi-statement function, returning the qualifying ids in a table variable:
-- Returns Example ids matching all provided (non-null) trigrams CREATE FUNCTION dbo.Example_GetTrigramMatchIDs ( @Trigram1 char(3), @Trigram2 char(3), @Trigram3 char(3) ) RETURNS @IDs table (id integer PRIMARY KEY) WITH SCHEMABINDING AS BEGIN IF @Trigram1 IS NOT NULL BEGIN IF @Trigram2 IS NOT NULL BEGIN IF @Trigram3 IS NOT NULL BEGIN -- 3 trigrams available INSERT @IDs (id) SELECT ET1.id FROM dbo.ExampleTrigrams AS ET1 WHERE ET1.trigram = @Trigram1 INTERSECT SELECT ET2.id FROM dbo.ExampleTrigrams AS ET2 WHERE ET2.trigram = @Trigram2 INTERSECT SELECT ET3.id FROM dbo.ExampleTrigrams AS ET3 WHERE ET3.trigram = @Trigram3 OPTION (MERGE JOIN); END; ELSE BEGIN -- 2 trigrams available INSERT @IDs (id) SELECT ET1.id FROM dbo.ExampleTrigrams AS ET1 WHERE ET1.trigram = @Trigram1 INTERSECT SELECT ET2.id FROM dbo.ExampleTrigrams AS ET2 WHERE ET2.trigram = @Trigram2 OPTION (MERGE JOIN); END; END; ELSE BEGIN -- 1 trigram available INSERT @IDs (id) SELECT ET1.id FROM dbo.ExampleTrigrams AS ET1 WHERE ET1.trigram = @Trigram1; END; END; RETURN; END;
The estimated execution plan for this function shows the strategy:
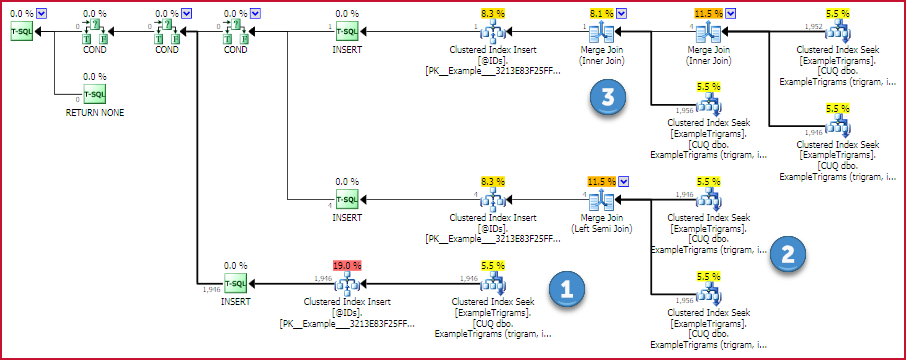
Trigram match ids plan
If there is one trigram available, a single seek into the trigram table is performed. Otherwise, two or three seeks are performed and the intersection of ids found using an efficient one-to-many merge(s). There are no memory-consuming operators in this plan, so no chance of a hash or sort spill.
Continuing the example search, we can find ids matching the available trigrams by applying the new function:
SELECT EGTMID.id FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT CROSS APPLY dbo.Example_GetTrigramMatchIDs (EGBT.trigram1, EGBT.trigram2, EGBT.trigram3) AS EGTMID;
This returns a set like the following:

Matching IDs
The actual (post-execution) plan for the new function shows the plan shape with three trigram inputs being used:
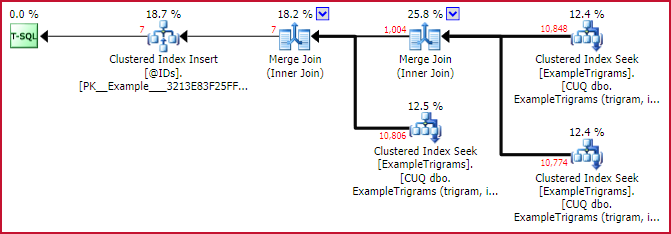
Actual ID matching plan
This shows the power of trigram matching quite well. Although all three trigrams each identify around 11,000 rows in the Example table, the first intersection reduces this set to 1,004 rows, and the second intersection reduces it to just 7.
Complete trigram search implementation
Now that we have the ids matching the trigrams, we can look up the matching rows in the Example table. We still need to apply the original search condition as a final check, because trigrams may generate false positives (but not false negatives). The final issue to address is that the previous stages may not have found any trigrams. This might be, for example, because the search string contains too little information. A search string of '%FF%' cannot use trigram search because two characters are not enough to generate even a single trigram. To handle this scenario gracefully, our search will detect this condition and fall back to a non-trigram search.
The following final inline function implements the required logic:
-- Search implementation CREATE FUNCTION dbo.Example_TrigramSearch ( @Search varchar(255) ) RETURNS table WITH SCHEMABINDING AS RETURN SELECT Result.string FROM dbo.Example_GetBestTrigrams(@Search) AS GBT CROSS APPLY ( -- Trigram search SELECT E.id, E.string FROM dbo.Example_GetTrigramMatchIDs (GBT.trigram1, GBT.trigram2, GBT.trigram3) AS MID JOIN dbo.Example AS E ON E.id = MID.id WHERE -- At least one trigram found GBT.trigram1 IS NOT NULL AND E.string LIKE @Search UNION ALL -- Non-trigram search SELECT E.id, E.string FROM dbo.Example AS E WHERE -- No trigram found GBT.trigram1 IS NULL AND E.string LIKE @Search ) AS Result;
The key feature is the outer reference to GBT.trigram1 on both sides of the UNION ALL. These translate to Filters with start-up expressions in the execution plan. A start-up filter only executes its subtree if its condition evaluates to true. The net effect is that only one part of the union all will be executed, depending on whether we found a trigram or not. The relevant part of the execution plan is:
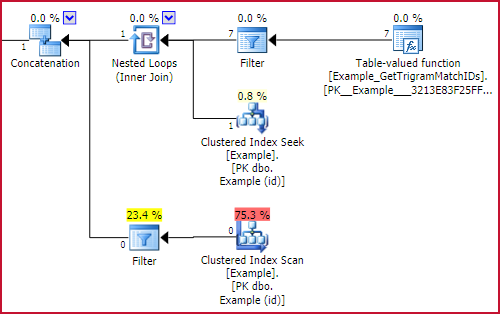
Start-up filter effect
Either the Example_GetTrigramMatchIDs function will be executed (and results looked up in Example using a seek on id), or the Clustered Index Scan of Example with a residual LIKE predicate will run, but not both.
Performance
The following code tests the performance of trigram search against the equivalent LIKE:
SET STATISTICS XML OFF DECLARE @S datetime2 = SYSUTCDATETIME(); SELECT F2.string FROM dbo.Example AS F2 WHERE F2.string LIKE '%1234%5678%' OPTION (MAXDOP 1); SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME()); GO SET STATISTICS XML OFF DECLARE @S datetime2 = SYSUTCDATETIME(); SELECT ETS.string FROM dbo.Example_TrigramSearch('%1234%5678%') AS ETS; SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
These both produce the same result row(s) but the LIKE query runs for 2100ms, whereas the trigram search takes 15ms.
Even better performance is possible. Generally, performance improves as the trigrams become more selective, and fewer in number (below the maximum of three in this implementation). For example:
SET STATISTICS XML OFF DECLARE @S datetime2 = SYSUTCDATETIME(); SELECT ETS.string FROM dbo.Example_TrigramSearch('%BEEF%') AS ETS; SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
That search returned 111 rows to the SSMS grid in 4ms. The LIKE equivalent ran for 1950ms.
Maintaining the trigrams
If the target table is static, there is obviously no problem keeping the base table and related trigram table synchronized. Likewise, if the search results are not required to be completely up to date at all times, a scheduled refresh of the trigram table(s) may work well.
Otherwise, we can use some fairly simple triggers to keep the trigram search data synchronized to the underlying strings. The general idea is to generate trigrams for deleted and inserted rows, then add or delete them in the trigram table as appropriate. The insert, update, and delete triggers below show this idea in practice:
-- Maintain trigrams after Example inserts CREATE TRIGGER MaintainTrigrams_AI ON dbo.Example AFTER INSERT AS BEGIN IF @@ROWCOUNT = 0 RETURN; IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN; SET NOCOUNT ON; SET ROWCOUNT 0; -- Insert related trigrams INSERT dbo.ExampleTrigrams (id, trigram) SELECT INS.id, GT.trigram FROM Inserted AS INS CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT; END;
-- Maintain trigrams after Example deletes CREATE TRIGGER MaintainTrigrams_AD ON dbo.Example AFTER DELETE AS BEGIN IF @@ROWCOUNT = 0 RETURN; IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN; SET NOCOUNT ON; SET ROWCOUNT 0; -- Deleted related trigrams DELETE ET WITH (SERIALIZABLE) FROM Deleted AS DEL CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT JOIN dbo.ExampleTrigrams AS ET ON ET.trigram = GT.trigram AND ET.id = DEL.id; END;
-- Maintain trigrams after Example updates CREATE TRIGGER MaintainTrigrams_AU ON dbo.Example AFTER UPDATE AS BEGIN IF @@ROWCOUNT = 0 RETURN; IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN; SET NOCOUNT ON; SET ROWCOUNT 0; -- Deleted related trigrams DELETE ET WITH (SERIALIZABLE) FROM Deleted AS DEL CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT JOIN dbo.ExampleTrigrams AS ET ON ET.trigram = GT.trigram AND ET.id = DEL.id; -- Insert related trigrams INSERT dbo.ExampleTrigrams (id, trigram) SELECT INS.id, GT.trigram FROM Inserted AS INS CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT; END;
The triggers are pretty efficient, and will handle both single- and multi-row changes (including the multiple actions available when using a MERGE statement). The indexed view over the trigrams table will be automatically maintained by SQL Server without us needing to write any trigger code.
Trigger operation
As an example, run a statement to delete an arbitrary row from the Example table:
-- Single row delete DELETE TOP (1) dbo.Example;
The post-execution (actual) execution plan includes an entry for the after delete trigger:

Delete trigger execution plan
The yellow section of the plan reads rows from the deleted pesudo-table, generates trigrams for each deleted Example string (using the familiar plan highlighted in green), then locates and deletes the associated trigram table entries. The final section of the plan, shown in red, is automatically added by SQL Server to keep the indexed view up to date.
The plan for the insert trigger is extremely similar. Updates are handled by performing a delete followed by an insert. Run the following script to see these plans and confirm that new and updated rows can be located using the trigram search function:
-- Single row insert INSERT dbo.Example (string) VALUES ('SQLPerformance.com'); -- Find the new row SELECT ETS.string FROM dbo.Example_TrigramSearch('%perf%') AS ETS; -- Single row update UPDATE TOP (1) dbo.Example SET string = '12345678901234567890'; -- Multi-row insert INSERT dbo.Example WITH (TABLOCKX) (string) SELECT TOP (1000) REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') + RIGHT(NEWID(), 10) FROM master.dbo.spt_values AS SV1; -- Multi-row update UPDATE TOP (1000) dbo.Example SET string = '12345678901234567890'; -- Search for the updated rows SELECT ETS.string FROM dbo.Example_TrigramSearch('12345678901234567890') AS ETS;
Merge example
The next script shows a MERGE statement being used to insert, delete, and update the Example table all at once:
-- MERGE demo DECLARE @MergeData table ( id integer UNIQUE CLUSTERED NULL, operation char(3) NOT NULL, string char(20) NULL ); INSERT @MergeData (id, operation, string) VALUES (NULL, 'INS', '11223344556677889900'), -- Insert (1001, 'DEL', NULL), -- Delete (2002, 'UPD', '00000000000000000000'); -- Update DECLARE @Actions table ( action$ nvarchar(10) NOT NULL, old_id integer NULL, old_string char(20) NULL, new_id integer NULL, new_string char(20) NULL ); MERGE dbo.Example AS E USING @MergeData AS MD ON MD.id = E.id WHEN MATCHED AND MD.operation = 'DEL' THEN DELETE WHEN MATCHED AND MD.operation = 'UPD' THEN UPDATE SET E.string = MD.string WHEN NOT MATCHED AND MD.operation = 'INS' THEN INSERT (string) VALUES (MD.string) OUTPUT $action, Deleted.id, Deleted.string, Inserted.id, Inserted.string INTO @Actions (action$, old_id, old_string, new_id, new_string); SELECT * FROM @Actions AS A;
The output will show something like:

Action output
Final thoughts
There is perhaps some scope to speed up large delete and update operations by referencing ids directly instead of generating trigrams. This is not implemented here because it would require a new nonclustered index on the trigrams table, doubling the (already significant) storage space used. The trigrams table contains a single integer and a char(3) per row; a nonclustered index on the integer column would gain the char(3) column at all levels (courtesy of the clustered index, and the need for index keys to be unique at every level). There is also memory space to consider, since trigram searches work best when all reads are from cache.
The extra index would make cascading referential integrity an option, but that is often more trouble than it is worth.
Trigram search is no panacea. The extra storage requirements, implementation complexity, and impact on update performance all weigh heavily against it. The technique is also useless for searches that do not generate any trigrams (3 character minimum). Although the basic implementation shown here can handle many types of search (starts with, contains, ends with, multiple wildcards) it does not cover every possible search expression that can be made to work with LIKE. It works well for search strings that generate AND-type trigrams; more work is needed to handle search strings that require OR-type handling, or more advanced options like regular expressions.
All that said, if your application really must have fast wildcard string searches, n-grams are something to seriously consider.
Related content: One way to get an index seek for a leading %wildcard by Aaron Bertrand.
The post Trigram Wildcard String Search in SQL Server appeared first on SQLPerformance.com.